 Motivation
Motivation
Abstract
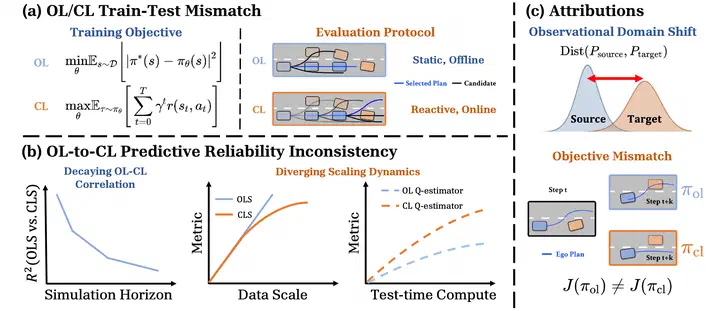
Open-loop (OL) to closed-loop (CL) gap (OL-CL gap) exists when OL-pretrained policies scoring high in OL evaluations fail to transfer effectively in closed-loop (CL) deployment. In this paper, we unveil the root causes of this systemic failure and propose a practical remedy. Specifically, we demonstrate that OL policies suffer from Observational Domain Shift and Objective Mismatch. We show that while the former is largely recoverable with adaptation techniques, the latter creates a structural inability to model complex reactive behaviors, which forms the primary OL-CL gap. We find that a wide range of OL policies learn a biased Q-value estimator that neglects both the reactive nature of CL simulations and the temporal awareness needed to reduce compounding errors. To this end, we propose a Test-Time Adaptation (TTA) framework that calibrates observational shift, reduces state-action biases, and enforces temporal consistency. Extensive experiments show that TTA effectively mitigates planning biases and yields superior scaling dynamics than its baseline counterparts. Furthermore, our analysis highlights the existence of blind spots in standard OL evaluation protocols that fail to capture the realities of closed-loop deployment.